Exploring Precision and Recall to assess the quality and diversity of LLMs
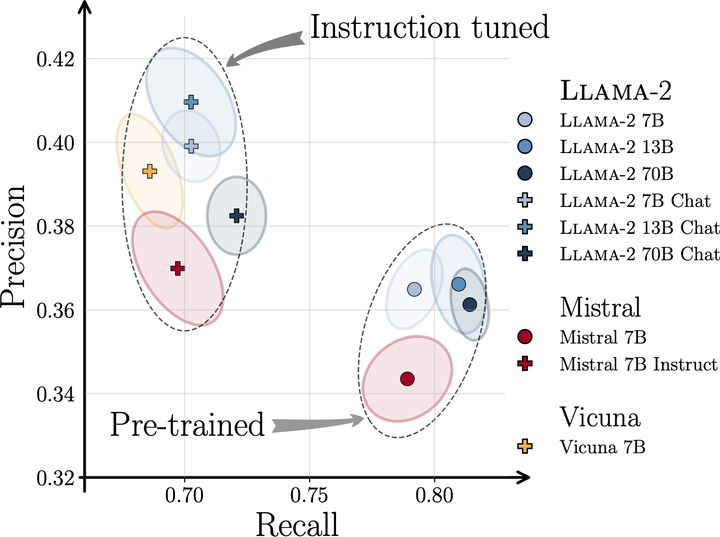 Quality and Diversity of the Pre-trained and Chat LLMs
Quality and Diversity of the Pre-trained and Chat LLMsAbstract
This paper introduces a novel evaluation framework for Large Language Models (LLMs) such as Llama-2 and Mistral, focusing on the adaptation of Precision and Recall metrics from image generation to text generation. This approach allows for a nuanced assessment of the quality and diversity of generated text without the need for aligned corpora. By conducting a comprehensive evaluation of state-of-the-art language models, the study reveals significant insights into their performance on open-ended generation tasks, which are not adequately captured by traditional benchmarks. The findings highlight a trade-off between the quality and diversity of generated samples, particularly when models are fine-tuned with human feedback. This work extends the toolkit for distribution-based NLP evaluation, offering insights into the practical capabilities and challenges faced by current LLMs in generating diverse and high-quality text.
Alexandre Vérine
Research Fellow IA
I am currently a Research Fellow at CSD at ENS PSL, specializing in Generative Models.